IRI Workbench supports the discovery and definition of disparate data sources in both local and remote systems.
Built-in data scanning, data profiling, data classification, and search results reporting -- along with field-metadata creation and management facilities -- directly support data integration, data masking, data migration, data quality, and related activities in the award-winning data processing and protection products front-ended in IRI Workbench.
ER Diagramming
Define enterprise-wide data class libraries, automatically search your sources and catalog the data in them, and then apply transformation and protection rules that you matched to your classes.
Read More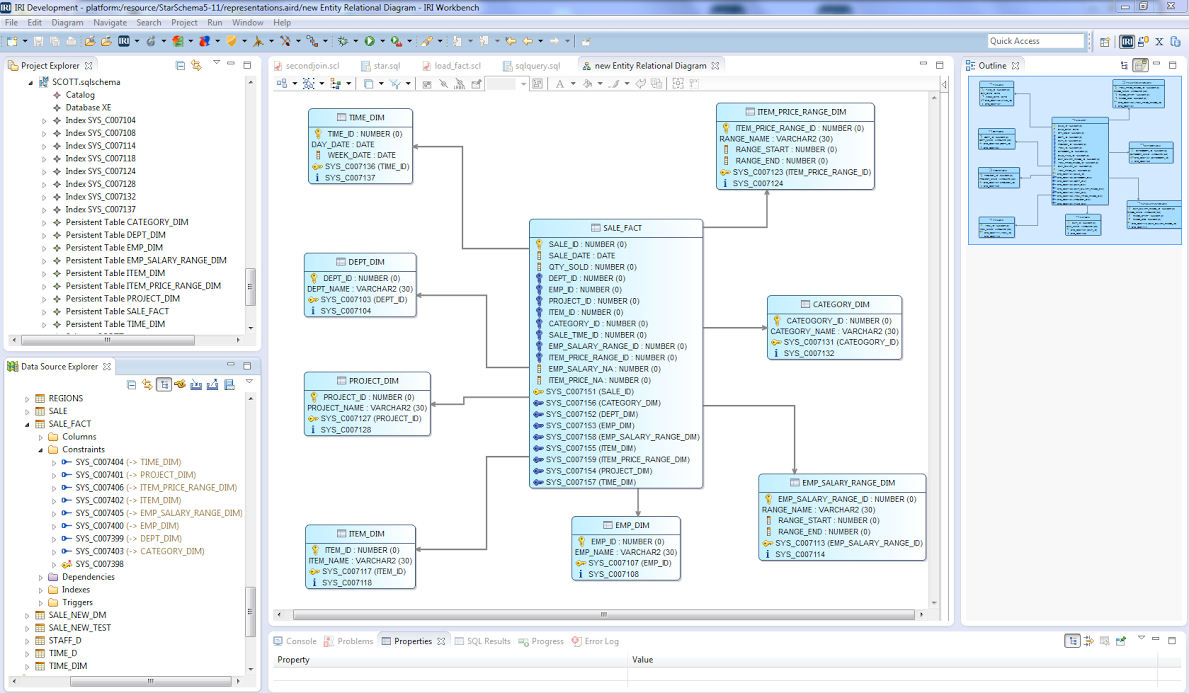
Data Classification
Define enterprise-wide data class libraries, automatically search your sources and catalog the data in them, and then apply transformation and protection rules that you matched to your classes.
Read More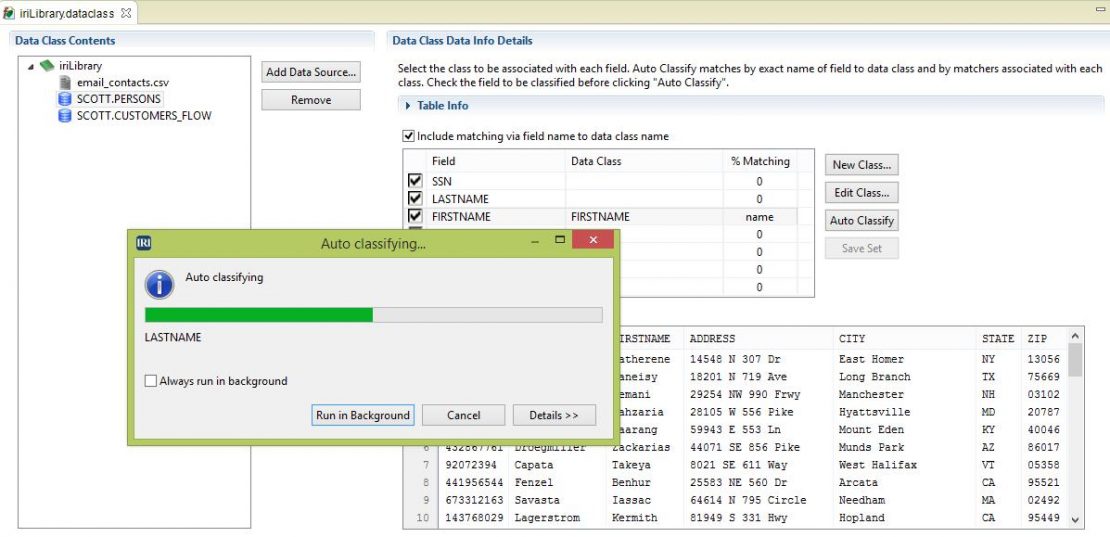
Metadata Discovery
Connect to structured and semi-structured files and relational databases. Define or re-define column names, offsets, and data types so you can save, share, and re-use the metadata for your data sources in central data definition files (DDFs) that are compatible with every IRI software application.
Read More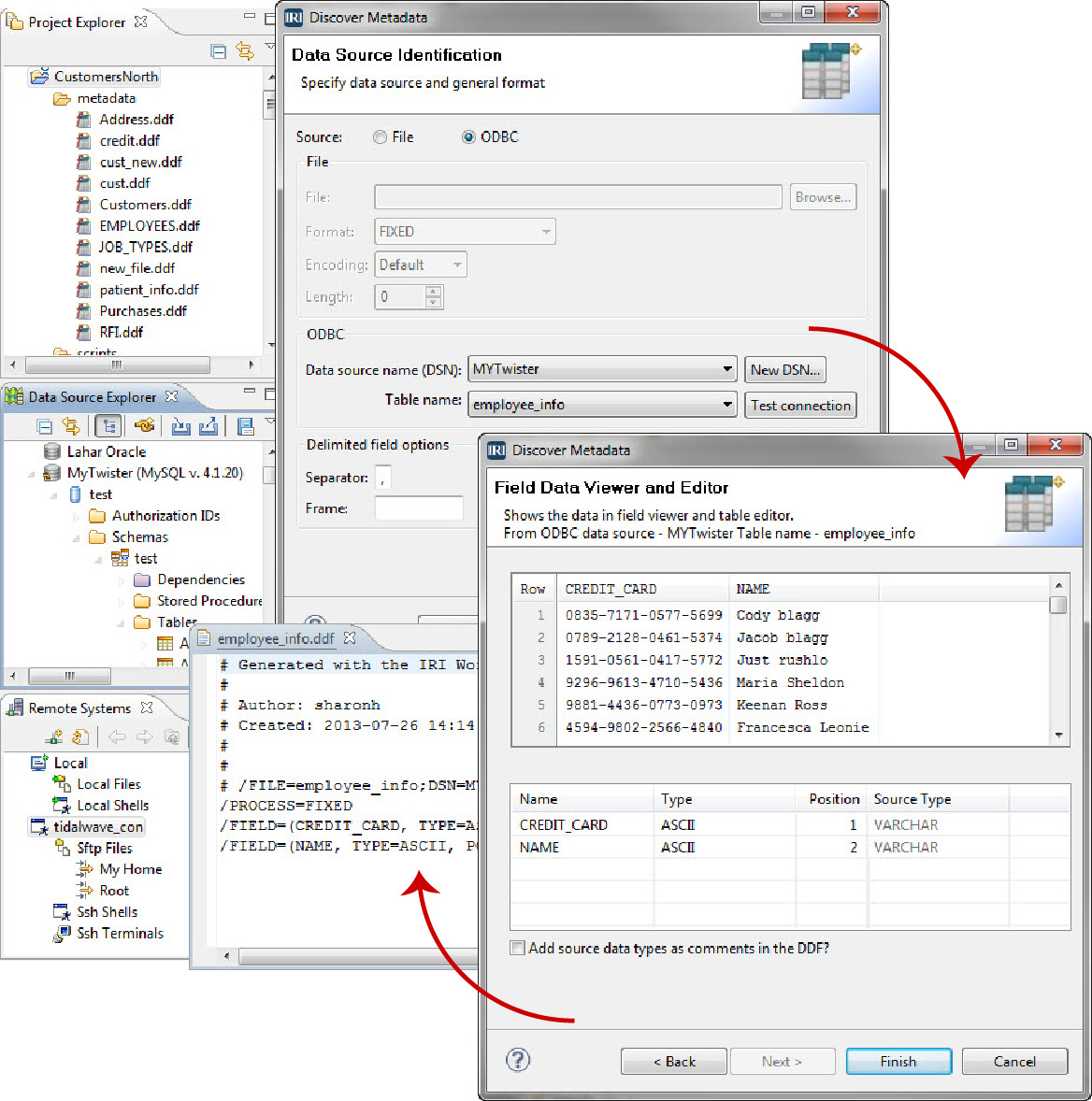
Metadata Imports
Integrated COBOL copybook and JCLsort parrmconverters, ASN.1 CDR and XLS/X file readers, XML and JSONparsers, and support for external data classification and discovery results also produce IRI-compatible data definitions or job configurations to save you time. In addition, third-party tools like Quest Mapping Manager, MITI MIMB and DataSwitch can automatically generate the same IRI DDF from a wide variety of ETL, BI and data modeling applications so you can be that much closer to processing the same data in the IRI Voracity platform to save time and money. Read More
Database Profiling
Compile statistics, check referential integrity, and search for lookup, string-, pattern-, and fuzzy-matching values in any JDBC-connected data source.
Read More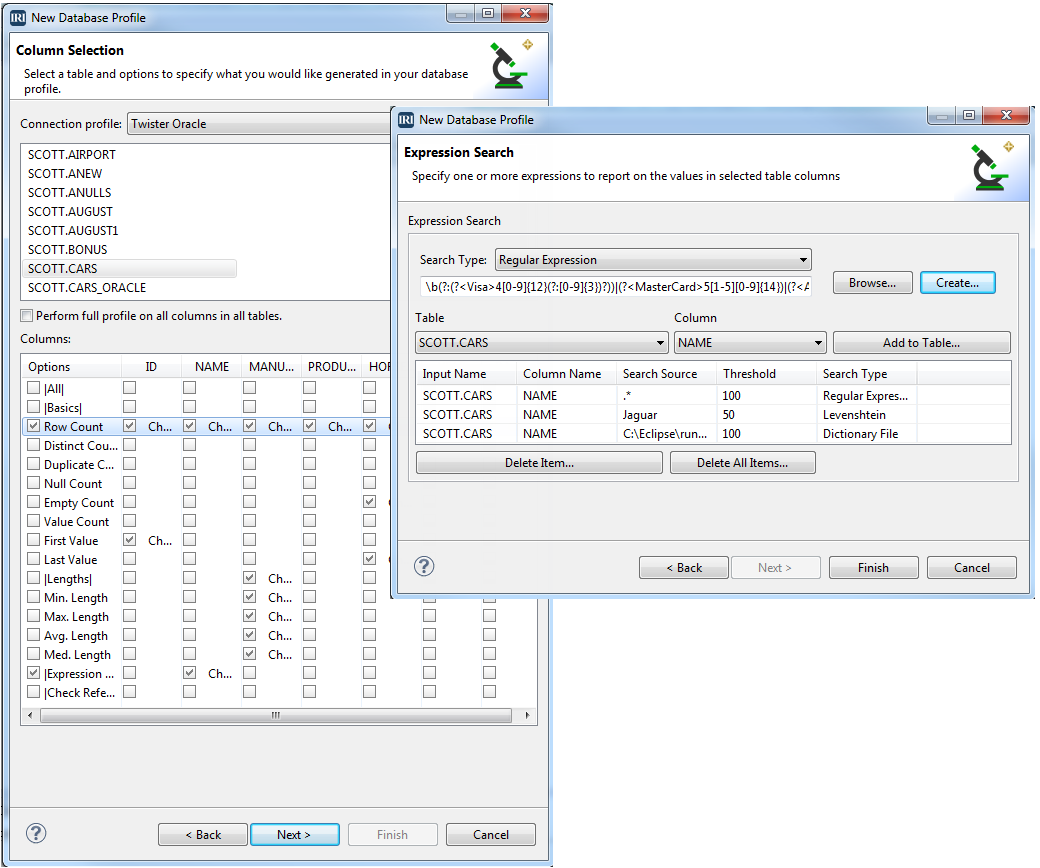
Flat-File Profiling
Compile statistics, and search for lookup, string-, pattern-, and fuzzy-matching values in any sequential file format that IRI supports.
Read More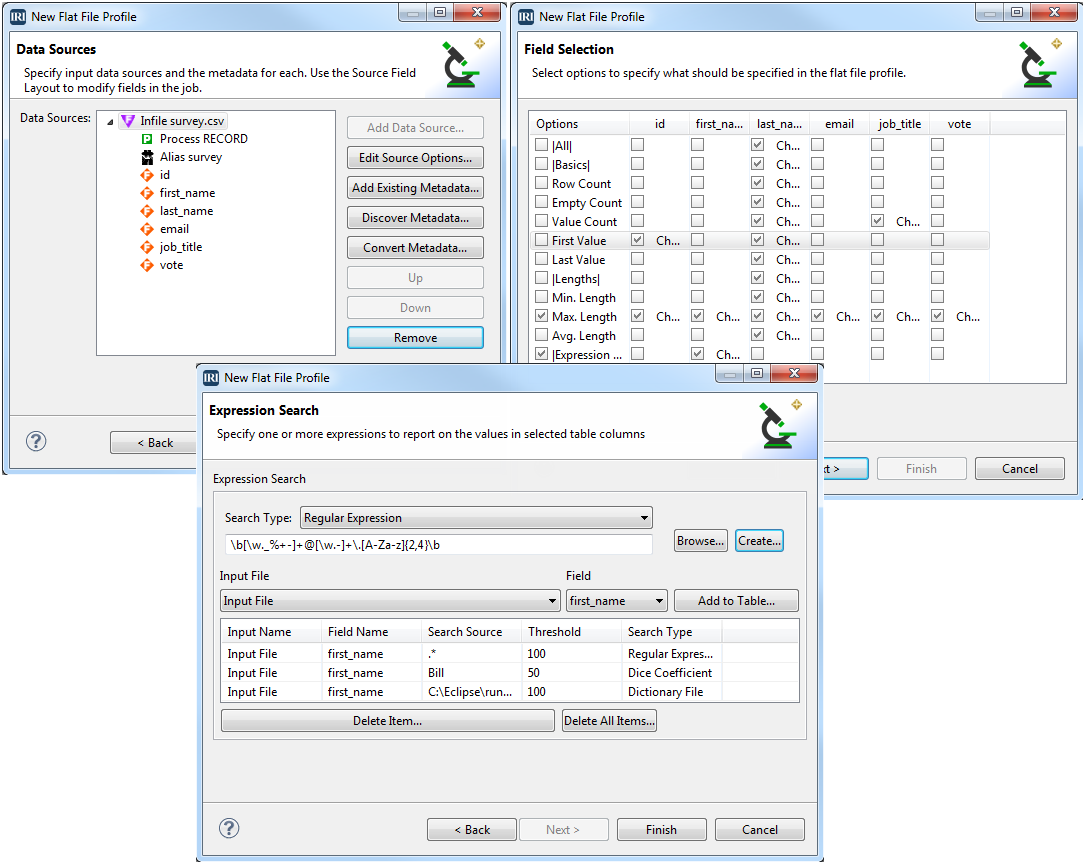
Schema Data Class Search
Find and leverage all data schema-wide that matches attributes of your data classes or data class groups. Automatically scan through every column in the schema rather than one table at a time. Use this in conjunction with the Data Class DB Masking wizard.
There is also a Directory Data Class Search (and corresponding Data Class File Masking) wizard in the IRI FieldShield menu in IRI Workbench to find and de-identify PII in one or more flat-files distributed across a LAN. Note that IRI DarkShield also supports the same data classes and masking functions for RDB schema as well; see the differences between FieldShield and DarkShield for RDB search/mask operations here.
Read More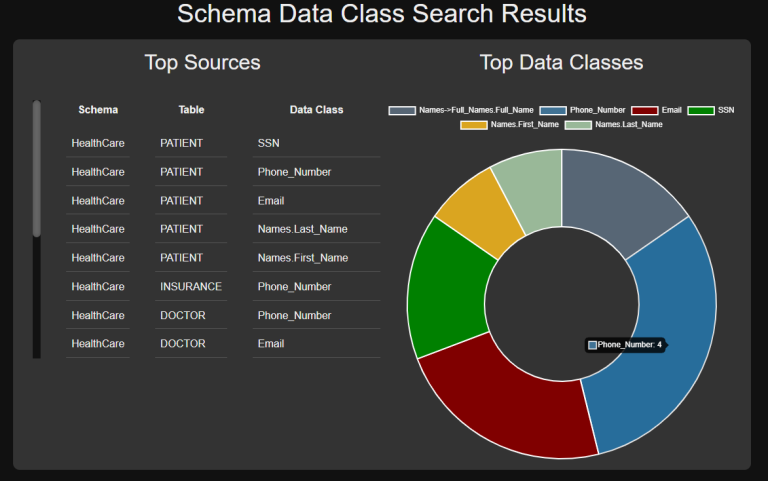
Directory Data Class Search
The Directory Data Class Search wizard in IRI Workbench (WB) matches data in structured files within one or more directories to configured data classes. The search process compares the matchers in the data classes with the data in those files to determine the best match, if any. The matchers can be either patterns or set file lookups. If only a few, selected structured files need to be searched, use the Data Class Library editor for faster results.
Read More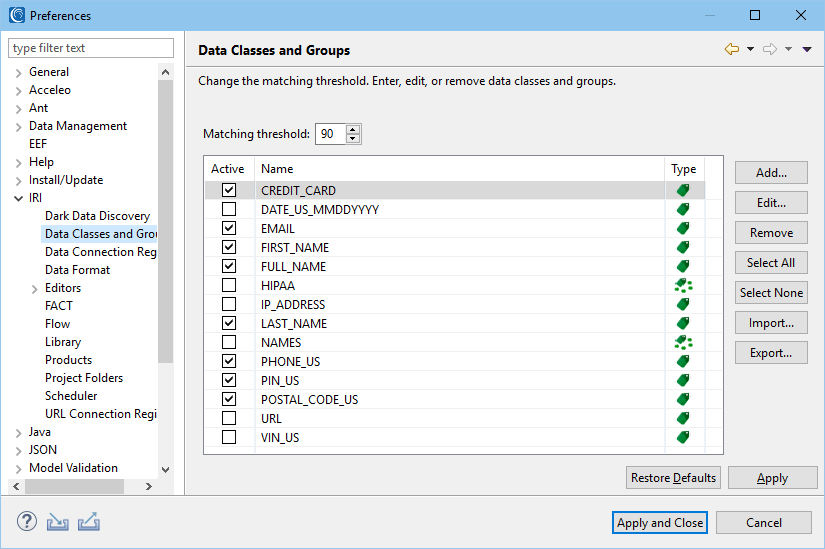
Dark Data Discovery
In addition to structured data, IRI DarkShield can also serach and report on data in semi-structured and unstructured sources on-premise or in the cloud, including: MS Office and PDF files, Parquet and audio files, relational and NoSQL databases, EDI files in FHIR, HL7, JSON, X12 and XML formats, raw text, and images in many formats including DICOM. Leverage one or more search methods at the same time, including metadata/location or Regex pattern matches, exact or fuzzy matches to lookup values, signature detection, and multiple NER model frameworks using semi-supervised machine learning. You can also extract values from dark data and its associated metadata into flat, query-ready DDF files and simultaneously mask or replace it with IRI DarkShield or perform textual ETL with Voracity.
Read More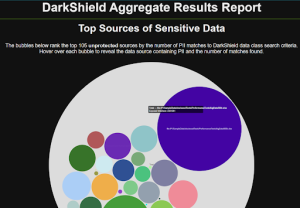
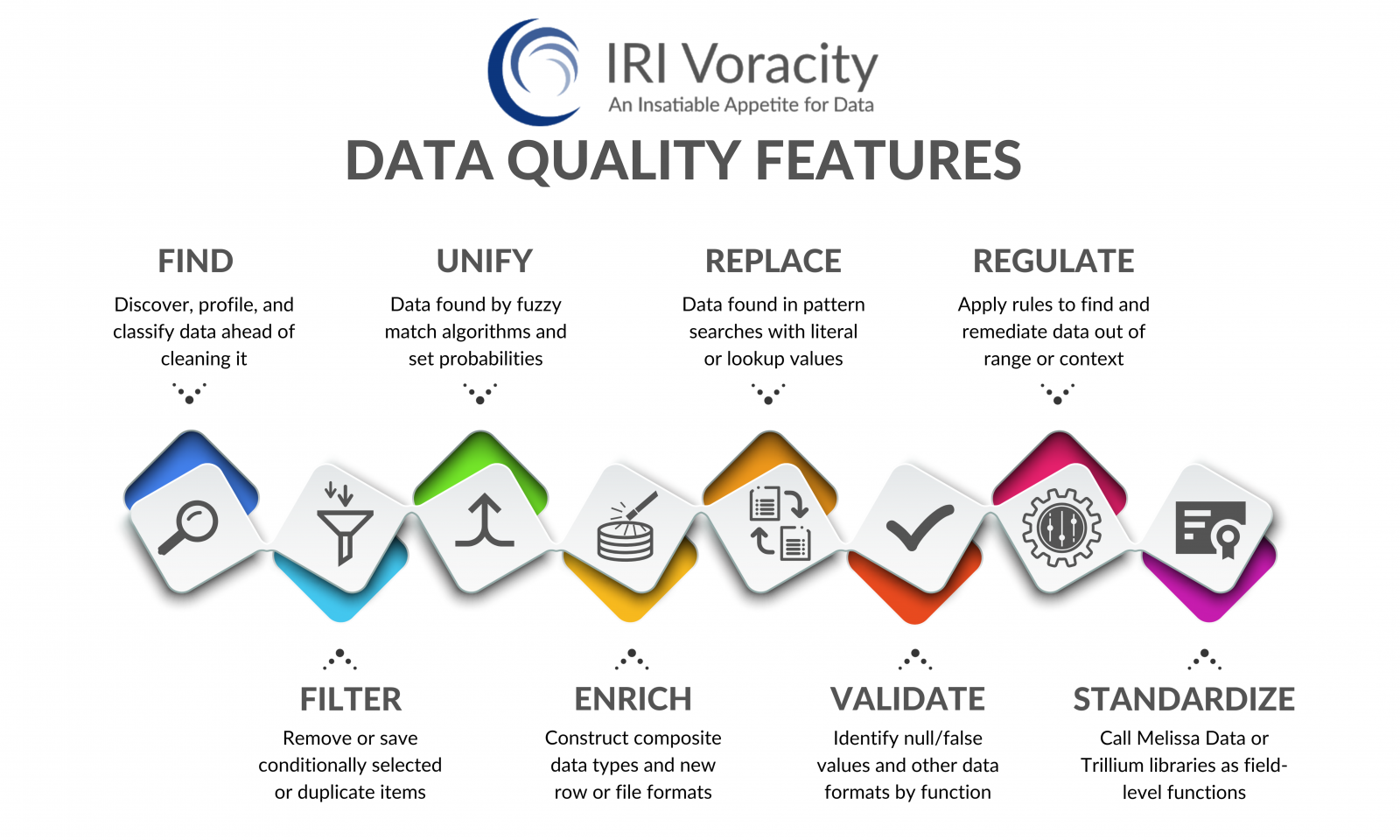
Data Quality Assessment
Use pattern definition and computational validation scripts to locate and verify the formats and values of data you define in data classes or groups (catalogs) for the purposes of discovery and function-rule assignment (e.g., in Voracity cleansing, transformation, or masking jobs). You can also use SortCL field-level if-then-else logic and "iscompare" functions to isolate null values and incorrect data formats in DB tables and flat files. Or, use outer joins to silo source values that do not conform to master (reference) data sets. Use data formatting templates and their date validation capabilities, for example, to check the correctness of input days and dates
Read More