Quick Links
Challenges
Normalized row and column data representations may require compaction to a de-normalized layout by rotating rows into columns. This is known as a pivot transformation and is a common requirement in statistical cross-tab reports. To pivot efficiently and prevent duplicate rows, the data should be pre-sorted. In other tools, that step is separate, and slow in volume.
Normalizing de-normalized content, or unpivoting presents other issues. For example, rows can have unexpected values or be missing entirely when the column values were null or zero. Sorting afterwards is again, typically a separate step.
Data pivot and unpivot commands in SQL, where available, are not always simple or portable across databases. ETL tools can require complex aggregate or union transforms (with "ports" and "expressions"), or specific pivot/unpivot transform editors with many properties to configure.
SQL CrossTab scripts are also clunky, and of no use for remapping fields and records in a flat file. XSL "for-each" transforms to flatten XML files are even more complex. Then there is the question of how all these methods perform in volume.
Solutions
The SortCL program in the IRI CoSort data manipulation utility or IRI Voracity ETL platform transposes rows and columns in pivot tables (or flat-files) while also supporting other transformation, cleansing, masking and reporting functions at the same time. You can define pivot operations or unpivot operations through an ergonomic job wizard in the IRI Workbench GUI, and/or simple 4GL job script.
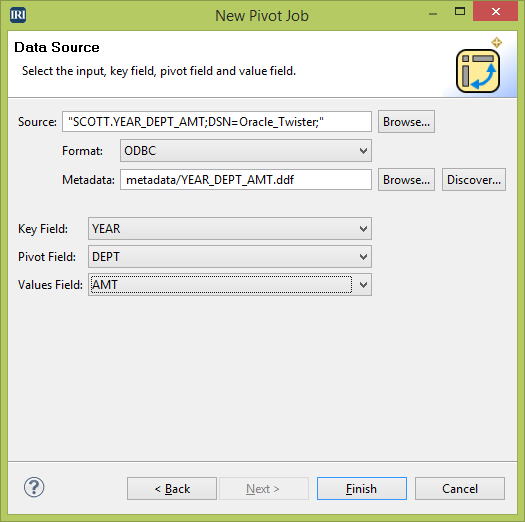
The New Pivot Job wizard in IRI Workbench takes you through the necessary column specifications for any data source.
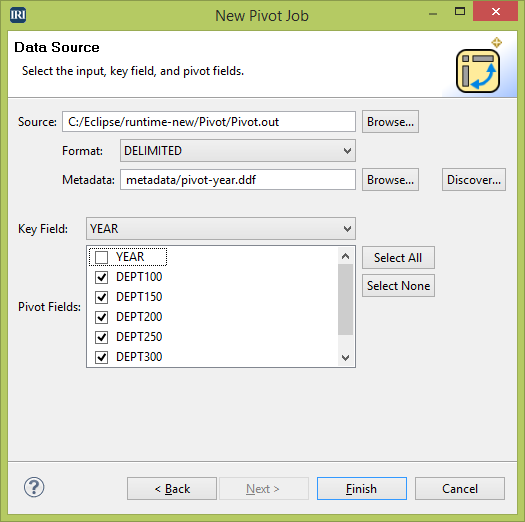
The same wizard can be used to unpivot as well ...
Related Solutions
