Challenges
Data cleansing solutions can be complicated, time-consuming, and expensive. The data quality functions you write in 3GL, shell scripts, or SQL procedures may be complex and hard to maintain. They also may not satisfy all of your business rules or do the whole job.
Custom data scrubbing techniques often run in separate batch steps, or in a special "script transform component" that you must connect to your tool's data flow and run in smaller chunks. This inefficiency is magnified amid high input data volume.
Data quality tools, on the other hand, can also perform a lot of this work. Unfortunately, they are not especially efficient in volume, and can be difficult to configure or modify. They may also be functional overkill, cannot be combined with related data operations, and/or cost too much.
Solutions
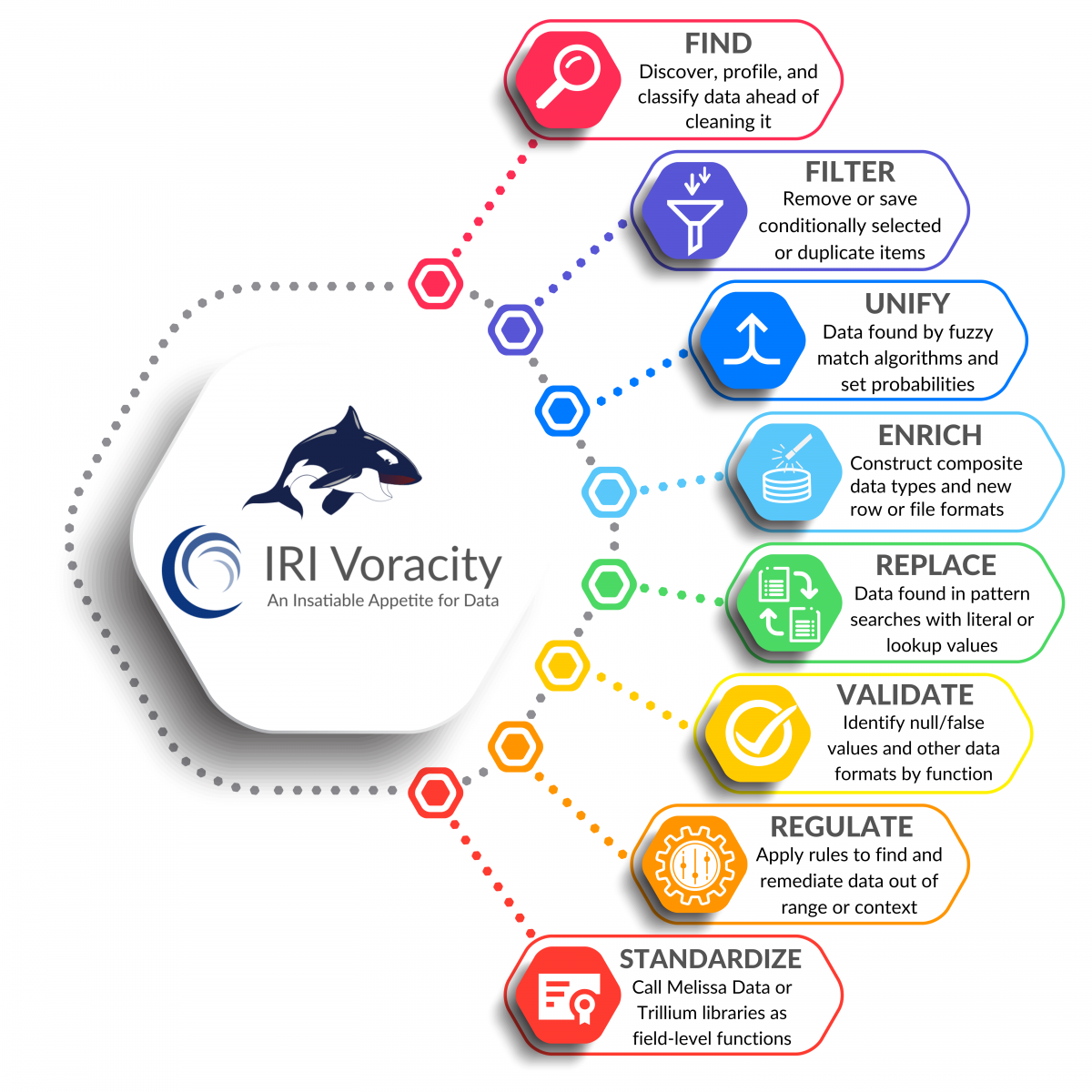
The SortCL program in IRI CoSort or IRI Voracity can find and scrub data in more than 125 table and file sources. SortCL uses a simple 4GL and Eclipse GUI to define not only your data cleaning functions, but its many other transformation, migration, and masking functions -- as well as your target tables and files (including reports) -- in granular detail..
The built-in data quality operations that IRI software allows you to perform -- or combine with those other activities -- include:
- de-duplication
- character validation
- data homogenization
- value find (scan) and replace
- horizontal, and conditional vertical selection
- data structure (format) definition and evaluation
- detection and flagging of data changes and logic problems
SortCL also supports the definition of custom data formats through template definitions. This allows for format scanning and verification.
For advanced data cleansing (based on complex business rules) at the field level, plug in your own functions or those in data quality vendor libraries. The CoSort documentation refers to examples from Trillium and the Melissa Data address standardization library. Declare a cleansing function for any field in either the pre-action layout or target phases of a job (i.e., up to two DQ routines per field, per job).
The bottom line? With CoSort SortCL -- and maybe specialized data quality libraries you add -- you can cleanse your data in the same I/O pass in which you filter, transform, secure, report on it, or hand it off.
If you need to find and scrub data sources for PII like SSNs, SortCL will do this too, as will the standalone IRI FieldShield data masking tool. If you need high quality test data, check out IRI RowGen. RowGen uses SortCL metadata to build intelligent, synthetic test data that conforms to your business rules so that you can test with the realistic, but safe: good, bad, and null data.
