Challenges
Data transformation, data remapping, data re-formatting, and reporting operations are often performed in slow, separate steps: e.g., sort, then join or aggregate, then hand-off a flat-file to a data quality or wrangling tool. Then the result of those processes gets opened in a data mart, BI tool, etc. All those I/O passes add up.
Sometimes complex languages like Perl or Python are used to recast data. Your data transformation technique may be hard to code or maintain over time, and in volume, run too slow.
Solutions
The SortCL data transformation program in the IRI CoSort data manipulation product and IRI Voracity data management (ETL) platform maps data using source column (field) names as symbolic references for mapping data to output. In combination with extensive, built-in data foramtting features, this mapping pass also allows you to recast, replicate, report on, and even virtualize (federate) data.
In other words, you can reformat and report on data in the same simple job script (and fast I/O pass) with ETL or other data migration, masking, cleansing, and wrangling operations. See all the data sources (and targets) supported here, and this sample job in the IRI Workbench GUI, built on Eclipse:
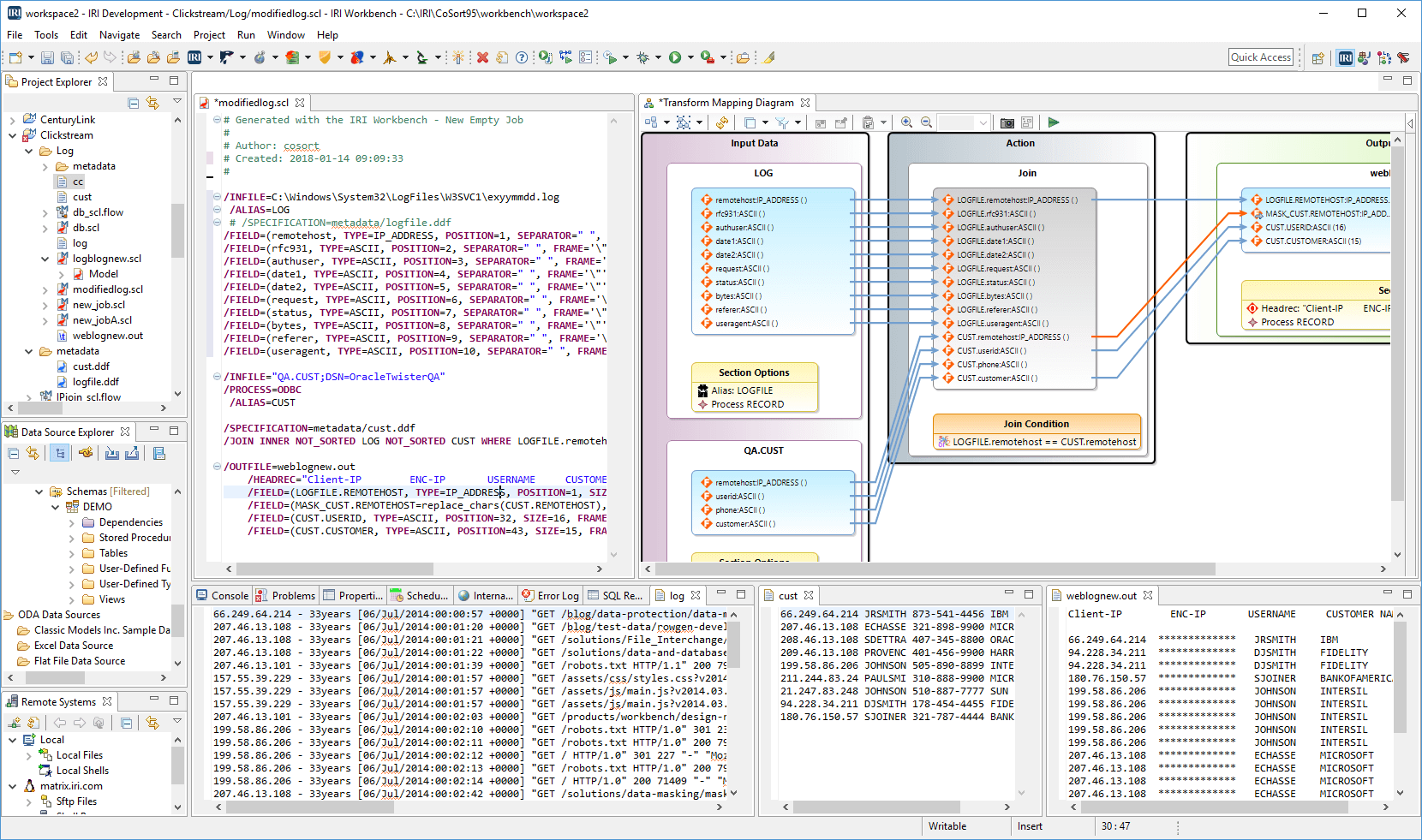
Specifically, as SortCL maps fixed- or variable-position fields from input to output, it can re-map (i.e., re-position, re-size, align, trim, pad), and type-convert the values. Additional custom layout options include changing fixed-position layouts to variable (floating) and vice versa.
Here are things IRI software users can do at the same time with the data they remap:
- Transform: filter, sort, join, aggregate, lookup, cross-calculate
- Cleanse: scrub, de-duplicate, validate, enrich, standardize
- Protect: encrypt, redact, pseudonymize, or otherwise obfuscate, anonymize or de-identify PII using masking rules
- Parse, strip, or rewrite header records on output. Insert special formatting characters and environment variables, including markup language commands for web-ready reports
- Perform mathematical expressions (cross-calculation) between field data, or on joined and/or aggregated values, to derive and output new detail or summary report values
- Create as many output targets and formats as you need in the same job script and I/O pass
- Reformat files from one type to another. For example, go from a COBOL index file to CSV and vice versa
- Append a "sequencer" field to each sorted record so you can cross-reference them by index values across multiple tables or files
- Populate targets directly through ODBC, pipes, or procedures, or feed them flat files for loading or further integration
