Challenges with CDI and Customer Segmentation
Customer Data Integration
CDI uses standard data integration techniques to represent a given customer across multiple points of contact (touchpoints) with your company. According to Acxiom, CDI involves:
- cleansing, updating, and completing missing customer contact data
- consolidating relevant records, purging duplicates, and joining records from disparate sources to enable customer (or donor) recognition at any touchpoint
- enriching internal and transactional data with external knowledge and segmentation
- complying with "contact suppression" and data privacy rules to protect the customer and the company
Customer Segmentation
Customer Segmentation helps you understand customers by demographic and purchase groups, so you can give them more of what they need, target your advertising, improve product delivery, and make investment decisions.
Together, CDI and segmentation can support corporate growth drivers, like customer relationship management (CRM), brand awareness, consumer loyalty, and IT initiatives such as business intelligence, predictive analytics, master data management (MDM), data loss prevention (DLP), and privacy law compliance.
There are several challenges along the road, however, that can make it hard to ascertain a customer overview or segment, or achieve the insights needed for better business decisions. For very large sets of data, customer segmentation analysis can be a slow and very difficult process using complex and costly platforms. It may expose sensitive data that requires specific, integration protection. Your current approach may also lack the audit trails from these processes that are needed for internal and external review.
Solutions for CDI and Customer Segmentation
Going against massive, flat-file and online (database / cloud CRM) sources of customer and transaction data, the Sort Control Language (SortCL) program in the IRI Voracity platform or subset IRI CoSort product gives you the ability to simultaneously integrate and report results on distinct subsets, view, or filtered groups.
Powerful selection, de-duplication, sort, join, aggregation, and reformatting functions combine CDI, staging, and segmented reporting in the same job script and I/O pass. Create as many outputs as necessary based on specified conditions and in individually customized formats.

Apply different selection criteria for customer segmentation, including:
- name, age, address, or date ranges
- account or other identifying numerics
- transaction or product (SKU) IDs
- web page visits or IP addresses
- new, changed, deleted, or duplicate data
Use built-in field-level encryption (or other privacy protection functions) to prevent the exposure of sensitive data on a need-to-know basis.
Each time SortCL runs, it can produce a complete XML audit log. This lets you examine the user, job, and runtime parameters to provide detective control and verify compliance with privacy regulations.
See More
Related Solution Areas
Data Integration & ETL IRI solutions for data integration and ETL. BI & Analytics IRI solutions for business intelligence and analytics.
BI & Analytics IRI solutions for business intelligence and analytics. 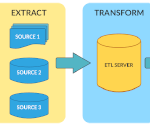 Data Governance Make the most out of stewarding data.
Data Governance Make the most out of stewarding data.  Change Data Capture Capture changes faster in a more functional way.
Change Data Capture Capture changes faster in a more functional way.  Clickstream Analytics Analyze clickstream patterns for decision making.
Clickstream Analytics Analyze clickstream patterns for decision making. 
IRI Products & Blog Articles
IRI Voracity A complete platform for data management and ETL. SortCL Metadata Learn about the metadata consistent across IRI products.
SortCL Metadata Learn about the metadata consistent across IRI products.  Business Intelligence Blogs A closer look at Business Intelligence.
Business Intelligence Blogs A closer look at Business Intelligence.  ETL Blogs A closer look at ETL.
ETL Blogs A closer look at ETL. 
