In a World of Big Data, Time to Insight Matters.
Data Quality and Security Do, Too.
The bigger the source data, the bigger the problems preparing it for Business Intelligence (BI) and analytics, as well as data science and AI models.
Volume
In performance terms, BI and analytic tools cannot process big data sets. If they work at all, they will take a long time to display results.
Variety
The myriad of structured, semi-structured, and unstructured data sources available today is beyond the read or processing capabilities of most COTS reporting solutions.
Velocity
BI tools usually cannot handle real-time or brokered data without pre-processing. And, if they can, feeding individual displays or data mesh data products -- rather than a governed subset -- creates redundancy and uncertainty.
Veracity
Garbage in, garbage out. Most BI tools and newer generation data preparation tools do not have the capacity to determine if data is clean nor scrub or standardize it when it is not. For information to be trusted and shared, inherent data quality is required.
Privacy
You may not have an effective strategy for masking sensitive data bound for reports. You may need a more convenient way to secure data at risk ahead of time, and maybe reveal it later.
Complexity
The design and modification of report and dashboard layouts are already complicated. Integrating data from disparate sources for every new report is another challenge for data and ETL architects, DBAs, and business uers. Data silos also create data quality, security, storage, and synchronization challenges.

Is there a way to address all of these problems at once ... to integrate, clean, and mask all this data so your analytic or data visualization tool can consume it?
Yes. This staging of re-usable data for consumption and display BI and analytic tools is called data blending, data preparation, data franchising, data munging, or data wrangling. This is such an important process that several VC-backed tools on the market were recently introduced just to tackle this challenge.
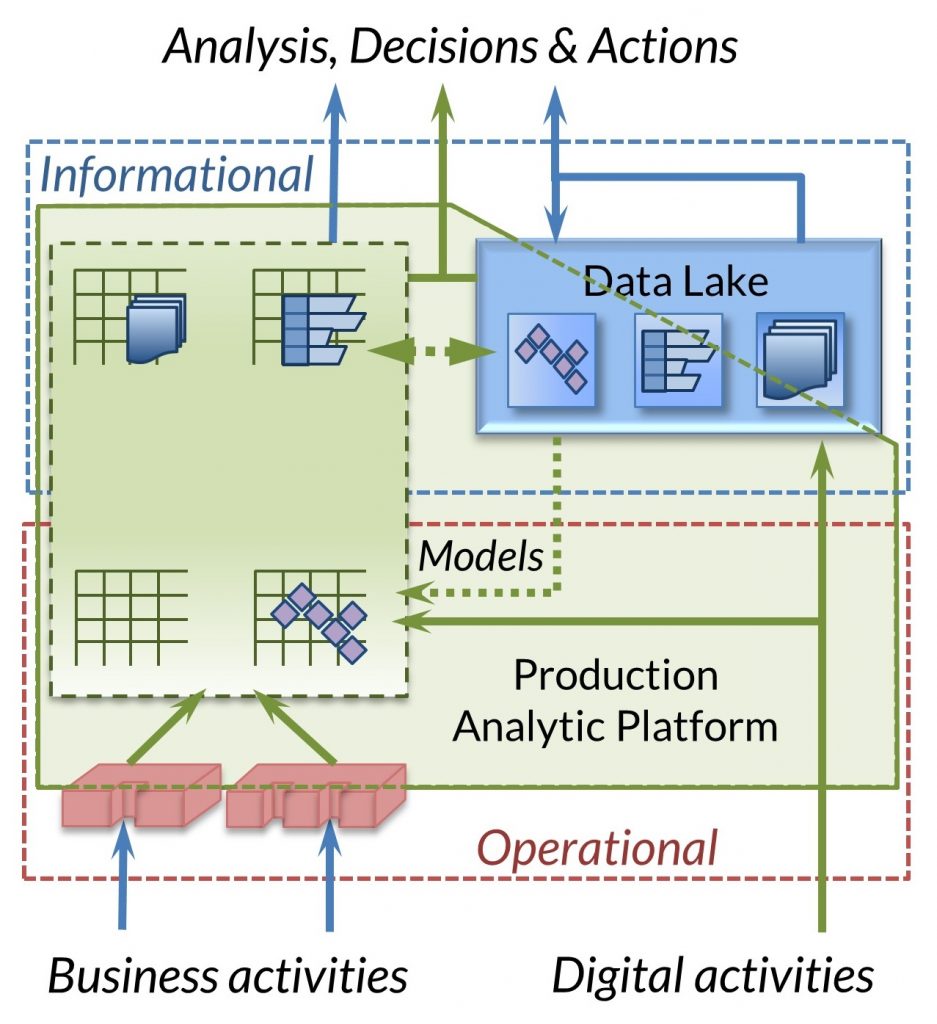
What you may not know however, is that the IRI CoSort data transformation and staging software package -- now also inside the IRI Voracity ETL platform -- has been both reporting on and handing-off data faster than anyone since 2003. In 2018, Voracity was declared a Production Analytic Platform by Data Warehouse industry founder Dr. Barry Devlin. In 2023, DBTA Magazine recognized Voracity as a good platform for data insfracture and federated governance in a Data Mesh.
See relative time-to-display benchmarks for your tool (in the tabs above).
Data integration, cleansing, and masking all run simultaneously in one consolidated SortCL program (the default CoSort and Voracity engine). Use it to rapidly and reliably wrangle and govern disparate data sources for use and re-use by your BI or analytic platform. Choose from multiple data preparation job design options in the free Eclipse™ GUI for Voracity, and process that data in Windows, Unix, or Hadoop file systems without buying more hardware or taxing a database.
Data Preparation (Wrangling)
In data preparation or wrangling, disparate sources of data are gathered, filtered, de-normalized, sorted, aggregated, protected, and reformatted. With this approach, your BI tool can import only the data it needs and in the table or flat file (e.g., CSV, XML) format it needs.
Data visualizations -- and thus answers to your business questions -- come faster when you use Voracity or CoSort to:
- Filter, scrub, join, aggregate, and otherwise transform big data in a single job script and I/O pass
- Build the subsets that dashboard, scatter plot, scorecard, or other analytic tools need and can handle.
Centralized data preparation also avoids reproducing or synchronizing data every time another report is need. Performing this work with software from IRI, The CoSort Company, also avoids the cost of megavendor and VC-funded products that need higher license fees to pay their investors back; we do not.
Data Protection (Masking)
De-identify PII feeding BI and analytic applications with built-in, field-level anonymization functions like:
- encoding
- ecnryption (format preserving or not)
- expressions
- hashing
- masking (obfuscation)
- randomization
- redaction
- sub-string manipulation
Apply the function you need -- using data classes and rules -- based on appearance, reversibility, and authorization.
Did You Also Know?
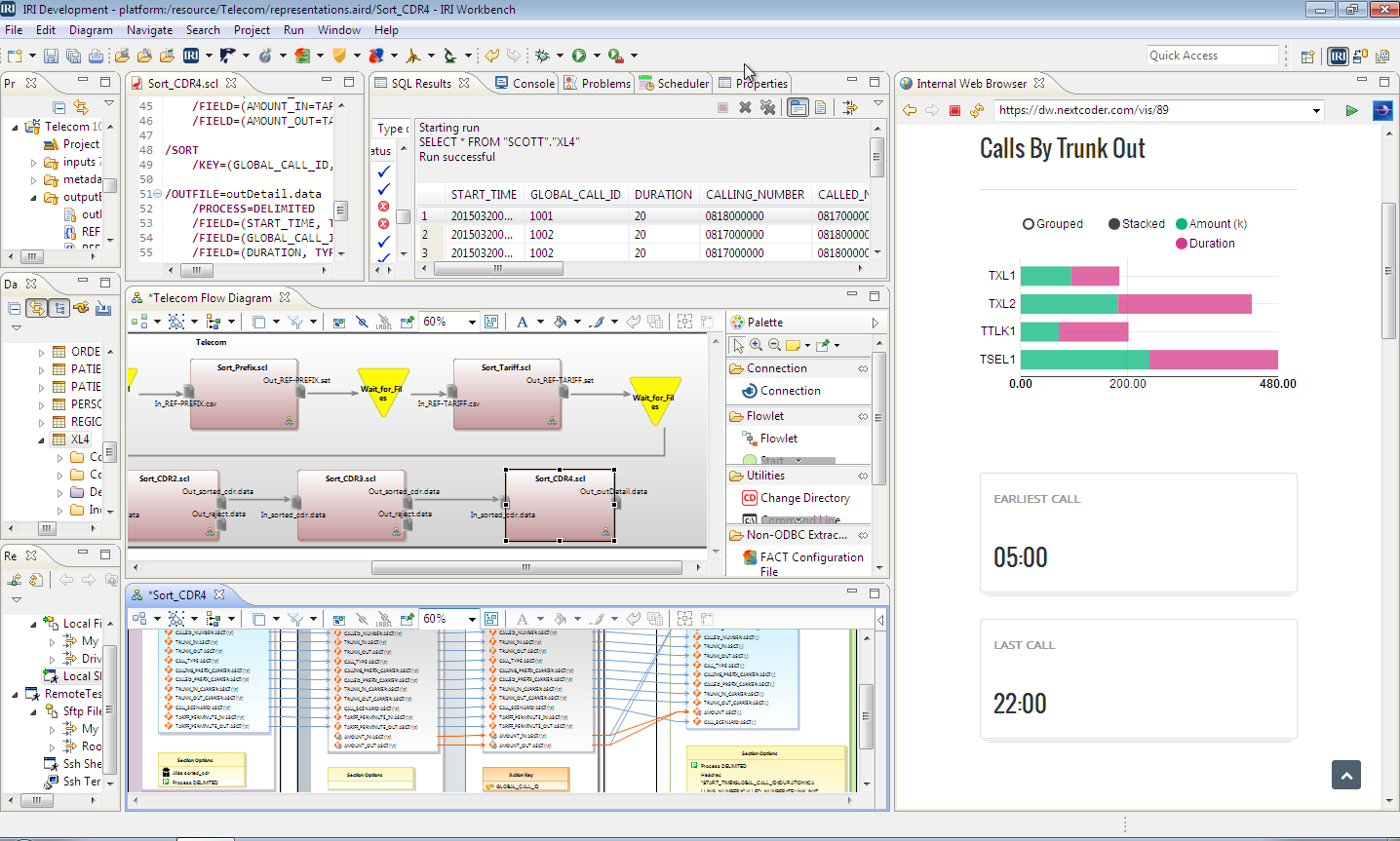
The free graphical IDE for job design across all IRI software products is called IRI Workbench. Built on Eclipse™, IRI Workbench supports:
- automatic data profiling, classification, ERD, and metadata creation
- job script (or flow) generation with multiple modification methods
- batch, remote, and HDFS execution
- data, metadata, and job version control
- master data management
Bottom Line
If you use an analytic or BI tool like BIRT, Business Objects, Cognos, DWDigest, Excel, iDashboards, KNIME, MicroStrategy, OBIEE, Power BI, QlikView, R, Splunk, Spotfire, or Tableau to integrate data now, you should consider offloading that burden to an engine and framework designed to do that well.
The fastest, most affordable, and robust environment for preparing data is IRI Voracity. Built on Eclipse™ and powered by CoSort or Hadoop engines, Voracity can discover (profile), integrate, migrate, govern, and prepare data for multiple BI and analytic targets at once.
If your data is already defined in another ETL or BI tool, the Erwin (AnalytiX DS) Mapping Manager and Meta Integration Model Bridge (MIMB) will automatically convert your source metadata into SortCL Data Definition Files (DDF). But if you don't have that metadata, it is easy to create and manage it in IRI Workbench as you map data from sources to targets. Processing, and reporting from and to, semi- and unstructured formats is possible as well.
