Big Data Packaging
According to the Open Knowledge Foundation, data packaging "is a simple way of putting collections of data and their descriptions in one place so that they can be easily shared and used" and that a data package is "in a format that is very simple, web friendly and extensible."
To IRI, and many people in the world of data processing and data science, data packaging is a manifestation of data integration, staging or wrangling operations, which, beyond data transformation and filtering, can also involve tasks like consolidation, cleansing, and anonymization.
IRI software has been packaging big data into usable, and meaningfully formatted result sets rapidly, reliably, and affordably for decades. Consider CoSort's traditional strength -- fast sorting -- and how essential that is to so many big data staging processes that also include lookups, joins, aggregations and remapping.
Today, you can leverage the CoSort engine or interchangeable Hadoop engines (MR2, Spark, Spark Stream, Storm, and Tez) within the IRI Voracity platform for total data management to package data in many ways. Combine, munge, cleanse, mask, and mine structured and semi-structured internal and 'open' sources for analytics, governance, and DevOps. There are also many things you can do with unstructured data discovered and extracted in Voracity.
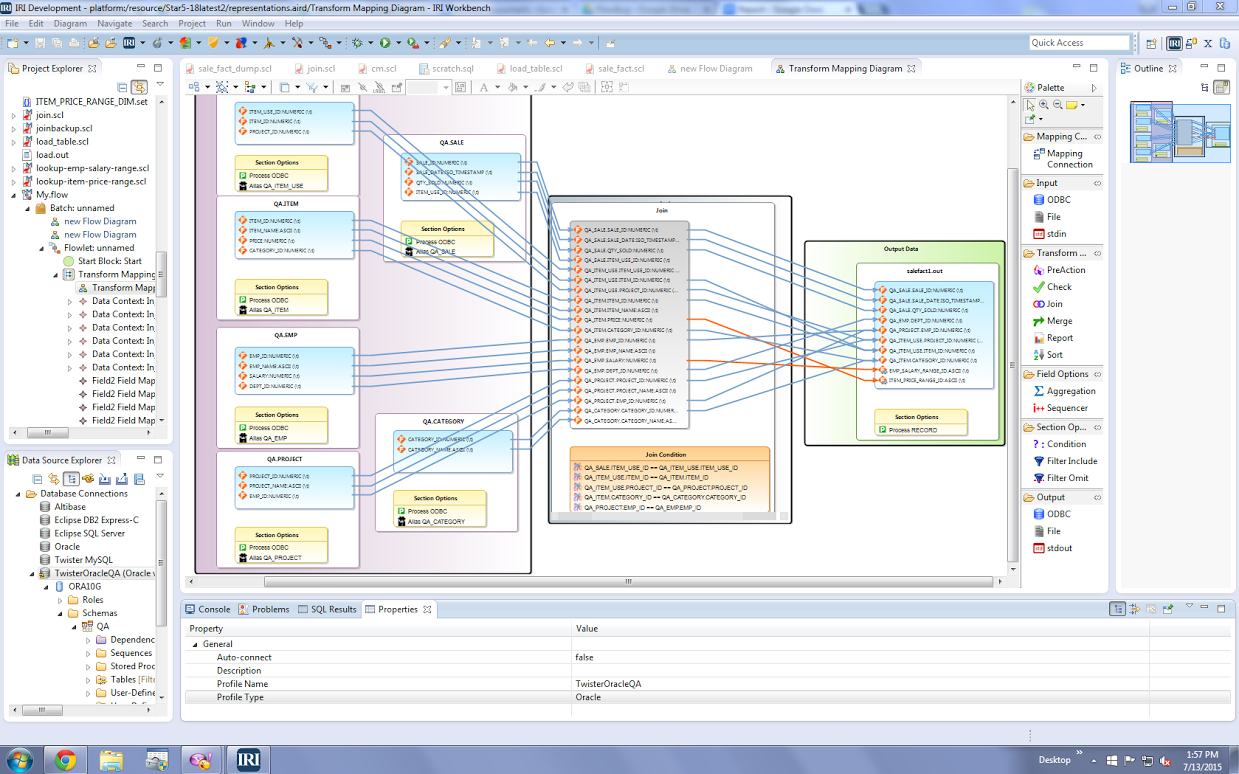
What Can I Do Specifically, and How Do I Do It?
More specifically, you can use the IRI Voracity "total data management" platform powered by CoSort (or Hadoop) in a data mesh, or as a Production Analytic Platform, as you package disparate sources of data. You can unify and distill related elements into multiple, purpose-built, custom-formatted targets ready for research and analytics in one or more line of business domains. With Voracity, you can do all of these things:
- Data Integration, including:
- Data acquisition (extraction), manipulation (transformation), and population (loading)
- Data filtering, cleansing and validation (data quality improvement)
- Data consolidation and standardization (MDM)
- Data federation and virtualization
- Data Reporting (embedded BI)
- Data Migration and Replication
- Data Classification, Scanning & Masking (see Big Data Protection)
- Test Data Generation (see Big Data Protection)
- Data Wrangling for BI tools like Qlik and Tableau, or analytic software like R or KNIME (see the Big Data Provisioning tab above, too).
Most of these activities can be specified and combined in wizard-driven, task-consolidating, single-IO job scripts, or well-diagrammed batch workflows that contain them. Using the intuitive diagrams or self-documenting text files they illustrate, you can easily understand, modify, run, schedule, and share your jobs.
Check out the award winning IRI 4GL program for data manipulation (SortCL), and the graphical IDE built on Eclipse (IRI Workbench) around it to create, automate and manage your data packaging jobs ... big or small, simple or complex, on-premise or in the cloud.
