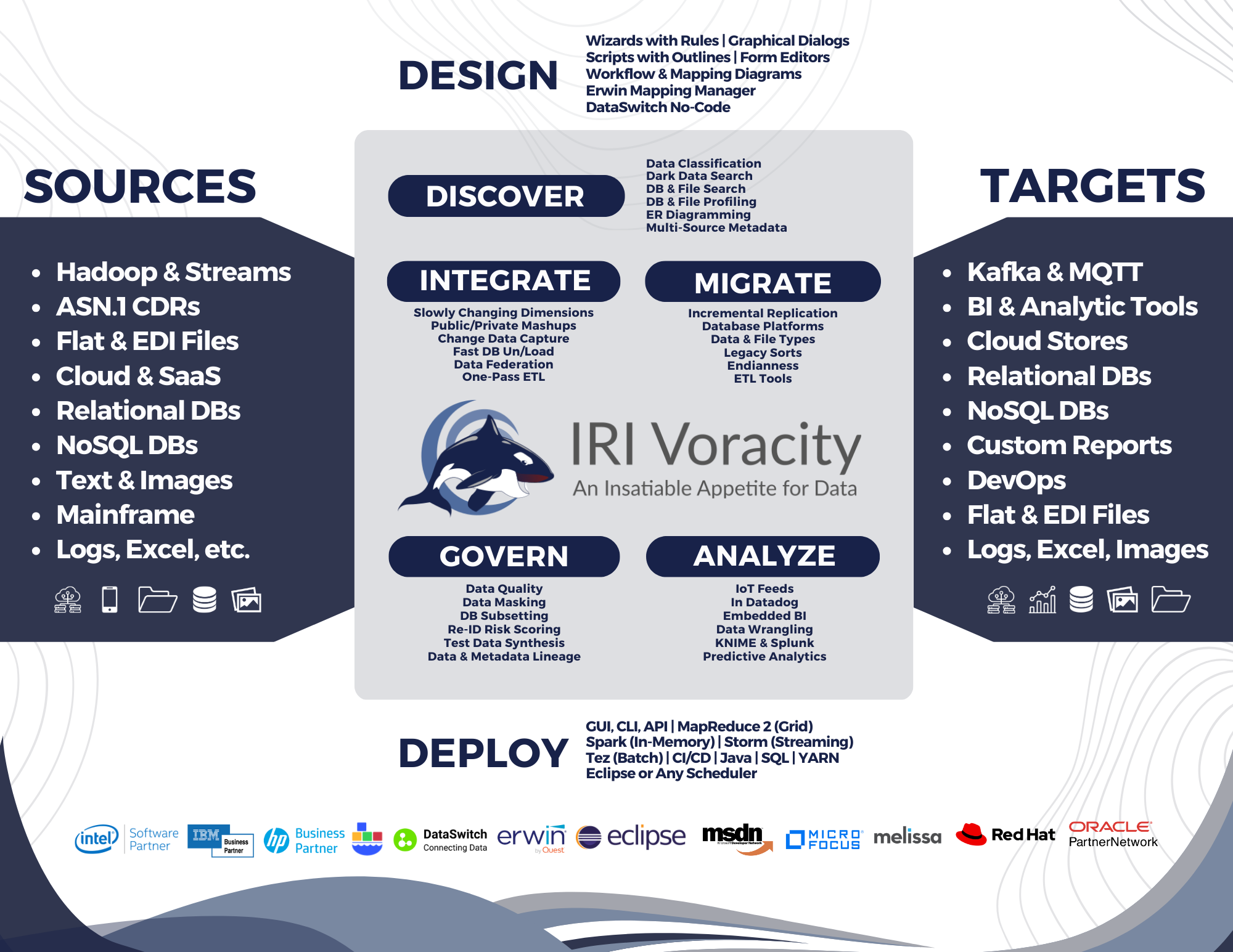
How Data is Integrated
In ETL (extract, transform, load) operations, data are extracted from different sources, transformed separately, and loaded to a data warehouse (DW) database and possibly other targets.
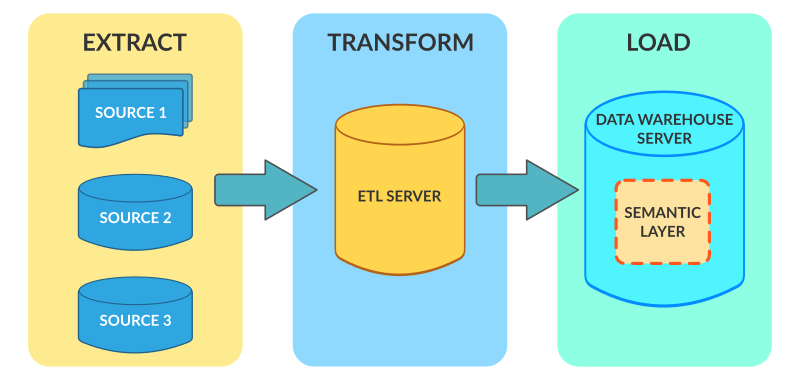
Data integration with ETL is often performed in legacy or cloud ETL tools, and sometimes in custom in-house programs. In almost every case, these solutions continue to suffer from a lack of performance in volume, an inability to adapt to the growing variety, velocity and veracity of data sources, implementation complexity, and high licensing and support costs.
Those weaknesses are all the more glaring when compared with the IRI Voracity data management platform, which has the highest price-performance ratio of any ETL software product the data warehousing industry.
Speed (and Price) Matters
Take a look at how Voracity uniquely optimizes and combines Extract, Transform, and Load operations:
Big Data: Rapid Acquisition
IRI supports a variety of high-performance extraction methods for static files and streaming data. Pump data in memory through pipes or procedures, web services, IoT devices, Kafka, and more.

VLDB Unloading: ODBC Select or "Fast Extract"

Very large database (VLDB) tables require a high-performance unloading (extraction) method for:
- Data warehouse ETL and ELT operations
- Classic (offline) reorgs
- Archival and storage
- Migration and replication
- Data interchange
IRI Voracity -- as well as its component products IRI CoSort (for data transformation and reporting), IRI NextForm (for data and database migration), and IRI FieldShield (for PII classification and masking) -- reads data directly from relational and NoSQL DBs via ODBC or native protocols. Or, you can dump huge RDB tables in parallel to flat files or stream their data through pipes using IRI FACT (Fast Extract) ... directly into the Voracity ETL workflow.
Extraction performance in DB and DW environments is constrained by high data volumes and inefficient approaches. Read about a remedy for big Oracle tables in this blog post.
Source-side selection in the Voracity CoSort engine via SQL and filtering commands in the CoSort SortCL program -- as well as change data capture (CDC) job scripts -- can improve acquisition performance by debulking source-side data. SortCL supports any number of input tables, files, pipes, and procedures at once, and can apply specific filtering criteria for every source independently or collectively through a virtual input record (inrec).
You can also extract values from semi-structured and unstructured sources into flat files, based on searches for literal strings and Java regular expressions (patterns). Multiple data discovery wizards, which also classify and profile the data in such sources, are included in the IRI Workbench GUI for Voracity, to help you find, structure, and use dark data, too.
For VLDB data acquisition, IRI FACT (Fast Extract) uses native drivers and parallel query methods to turn VLBD tables into flat files when bulk unloads are needed. FACT imposes no database overhead or configuration changes. FACT also bypasses the need to set up log sniffers and complex CDC in the database.
FACT uses SQL SELECT syntax in simple configuration files to unload data from: Oracle, DB2 UDB, Sybase, MS SQL Server, MySQL, Altibase, and Tibero.
During extraction, FACT reformats (e.g. delimiter) and converts the data (e.g. date types), and silos LOB fields. FACT also writes CoSort SortCL metadata for data transformation, conversion/replication, masking, and reporting, plus loader control file metadata for the source databases. This facilitates reorgs and ETL in the same I/O pass.
The IRI Workbench GUI for FACT, CoSort, etc. supports the automatic creation of tables and loader files for additional target databases including Teradata in Eclipse.
Optimize Each Transform
Voracity accelerates every essential data transformation process. It also optimizes ETL operations by combining sorts, joins, and aggregations in a single job script, partition, and I/O pass.
With Voracity, a decades-proven CoSort engine (or seamlessly interchangeable Hadoop engines) can transform massive volumes of data without using a DB, hand-coded Hadoop program, extra RAM or an expensive ELT appliance.
Combine Multiple Transformations
Voracity ETL software enables you to leverage multiple CPUs and cores (threads), execute multiple tasks in the same I/O pass, and dynamically allocate memory and disk usage. You can transform large data volumes from many different table and sources together. Simple text file metadata repositories, which you can manage and share as a catalog in IRI Workbench workspaces, allow you to discover, define, expose, and leverage your data sources.
Beat the steep costs and learning curves of other techniques with the easily understood, shared, and modified metadata that Voracity uses for data and job definition. You can learn how these underlying CoSort SortCL programs (and their reusable data definition files) optimize and consolidate data transformation in the Data Transformation section of the IRI web site.
If the fastest place to stage a data warehouse database (DB) is in the file system, what is the fastest way to load them? There are many ways to load relational DBs, including:
- single or bulk row inserts
- create or insert (with append hint) as select from another table
- conventional and direct path loads
Many DBAs do not know the fastest method, and instead use proprietary export/import tools that tax their databases and do not serve heterogeneous data warehouse architectures.
CoSort software in the IRI Data Manager suite or IRI Voracity (ETL) platform can create and populate any database table directly with either surgical or bulk methods. Voracity users can also load data into NoSQL DBs using files or connectors.
Use built-in ODBC create, insert, truncate, update and append functions inside CoSort SortCL data manipulation and mapping jobs as you define your targets. Or, use direct DB connection and SQL features built-into the Eclipse IRI Workbench GUI supporting CoSort, Voracity, FieldShield (data masking), NextForm (data/DB migration), etc.
Voracity ETL and other new job creation wizards in IRI Workbench provide automatic table creation and loader control file generation for targeting Altibase Loader, DB2 UDB Load, Oracle SQL*Loader, SQL Server and Sybase bcp, and Teradata fast and multi-load. This lets you leverage the fastest method for bulk loading relational DBs... pre-sorted files. See this article on High Speed DB Loading.
The CoSort data transformation phase of Voracity jobs can rapidly sort flat files in index order that RDB load utilities can rapidly pump into tables while bypassing slower, DB-taxing internal sorts. Having tables in order, and removing bulk transformation overhead from the DB layer, both improve query performance.
You can also use CoSort with or without Voracity to transform and report on big data so your DB does not have to. It's all about freeing up your DB for what it does best: store and query.
Because speed matters, Voracity is ideal as a standalone ETL tool for every major integration paradigm in big data environments. And because price matters, Voracity also gives you the ability to either speed or leave your current ETL tool.
Beyond ETL, Voracity also supports a number of related integration activities, ranging from federation and masking, to data quality and MDM. Click here for more information on these related capabilities and implementation considerations in Voracity. See also:
Voracity Advantages
Click on the boxes below to learn why Voracity is a better alternative for ETL operations and beyond:
Speed
IRI FACT (Fast Extract) uses native drivers to unload huge tables in parallel to flat files or pipes.
IRI CoSort takes the output of FACT from a file or in-memory stream (pipe) and does the heavy lifting of data transformation, load pre-sort, and reporting all in the same job script and I/O pass.
The IRI Voracity total data management platform combines FACT, CoSort, and bulk DB load utilities in a visualized, scheduled ETL workflow that does not require compilation or partitioning. It can even seamlessly run CoSort jobs in MapReduce, Spark, Storm, or Tez instead.
Compare all this to slower, more verbose SQL and 3GL programs, and to costlier, more complex ETL tools and ELT platforms ... not to mention the onboarding delays of disjointed Apache projects.
Simplicty
ETL metadata and job definition are automated in the IRI Workbench GUI for Voracity, built on Eclipse™. Data discovery and new job wizards, and a number of visual ETL job design options, speed-build reusable repositories and scripts without requiring and education in new syntax.
Nevertheless, Voracity metadata is the easiest in the IT industry to learn and use. It uses the same human-readable 4GL of CoSort-- called SortCL-- that leverages familiar data layout syntax, SQL manipulation concepts, and shared metadata repositories. Many users still prefer to code and tweak these simple scripts directly.
Versatility
Beyond extremely fast extract/load and one-pass, no-partitioning-needed data transformations, the Voracity ETL environment supports:
- Change Data Capture
- Dark Data Search/Extract/Structure
- Database and File Profiling
- Data Masking, Encryption, etc.
- Data Migration and Replication
- Metadata Creation, Conversion, and Sharing
- Detail and Summary Reporting
- Master Data Management (foundational)
- Metadata Management & Lineage
- Offline Reorgs
- Slowly Changing Dimensions
- Test Data Generation
- Database Subsetting
- Data Quality (Cleansing, Deduplication, Validation, Unification, Enrichment, Standardization)
Voracity supports these activities on a very broad range of structured, legacy, big data, cloud, and SaaS data sources.
Ergonomics
Create all the E, T, and L jobs in the IRI Workbench GUI for Voracity, built on Eclipse™. Edit the jobs or workflow palettes, GUI dialogs, syntax-aware script editors (or any text editor you prefer), or the erwin Mapping Manager. You have the ergonomic flexibility of working the data definitions and manipulations visually or through scripting; anything done in one feeds the other.
Test or run jobs individually or together in the GUI flow, or later in a (scheduled) batch operation. You have that execution flexibility because the job scripts are portable. You can run any of the pieces, or the whole project, on any platform where the engine(s) are licensed. Call them from the command line or any application.
Extensibility
The IRI Workbench GUI for Voracity delivers the visual metadata creation, conversion, and discovery tools you need to generate, deploy, and manage the job scripts, data definition files (DDF), and XML workflows common to most IRI software.
In the same pane of glass, you can design and run Python, Java, C++, Kotlin, Hive, Impala, Perl, Powershell, R, SQL, and other programs supported in Eclipse, and even incorporate them as steps in your Voracity workflow.
You can also use the SortCL program that powers CoSort in Voracity to optimize transforms for other ETL tools like Informatica and DataStage.
Economics
Voracity is far more than an ETL tool, yet is priced below most of them. Even if you do not use it for ETL, because its SortCL program can join across many sources and query data in flat files, Voracity continues in the CoSort tradition as one of the least expensive change data capture and NoSQL query paradigms available.
For serious ETL architects, however, the consolidation and multi-processing within Voracity transformation jobs -- in the file system or (seamlessly in) Hadoop -- makes Voracity the most cost-effective big data processing alternative to DB/ELT appliances, Ab Initio, SyncSort, Teradata, and in-memory DBs.
Finally, with its low-cost opex subscription tiers and relative simplicity, Voracity is the most affordable data management platform to on-board and maintain.