Through its Workbench GUI, IRI Voracity® offers more data management job debugging and deployment options than any other platform, and all in one place.
Voracity's workflow palette allows you to design one or more applications (flowlets) into a larger project (flow), complete with intra-task properties and runtime previews at any step along the way ... plus inter-task dependencies that are also reflected in the open XML metadata defining every aspect of your jobs, regardless of syntax.
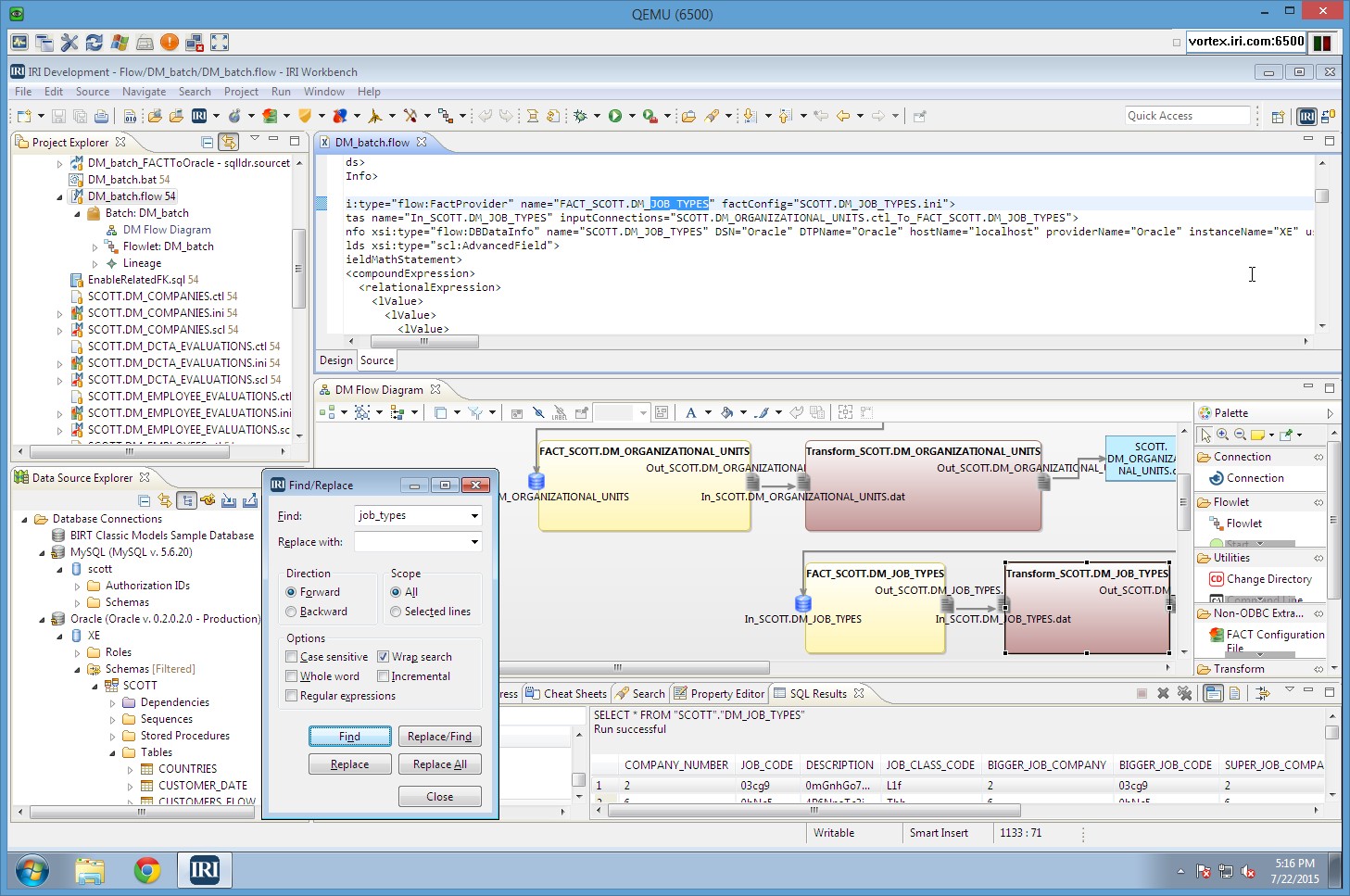
Voracity flow files can include IRI FACT config files, IRI CoSort SortCL .DDF and all valid .*cl manipulation job scripts, multiple DB loader control files, SQL procedures , Java programs, and O/S (shell) commands.
At any point in the process, Voracity provides feedback through the intra-project (inter-task) display feature. Examine or share a sample of the results from one or more parts of an operation in the preview window before you run the entire job. The task preview feature can run with source or synthetic test data.
Toggle warnings and view error messages, log application statistics and runtime performance, and send audit trails to designated file targets, email recipients, and cloud-sharing users.
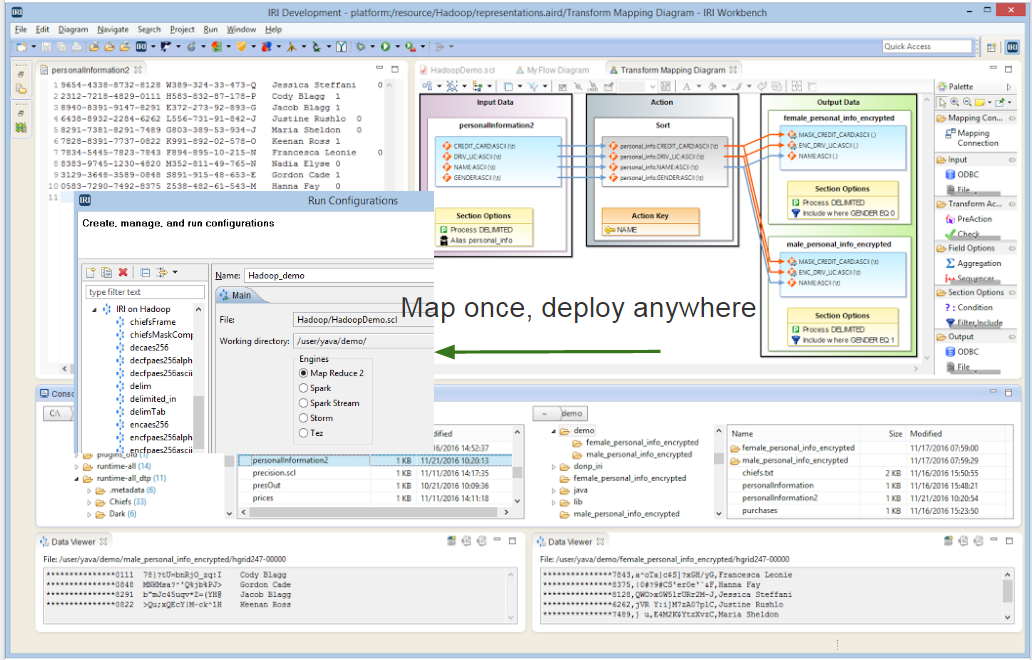
Once you are satisfied, it's time to move into production, you can run your job(s) with the CoSort engines in the base Voracity package on the local (client) machine, or remote Windows, Linux, or Unix server. You can also run most of the same jobs with no changes in Hadoop MapReduce, Spark, Spark Stream, Storm, or Tez engines... and again, all within the same "pane of glass":
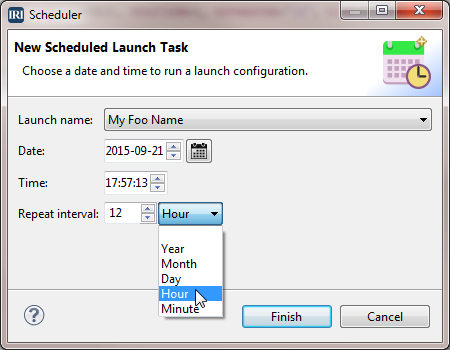
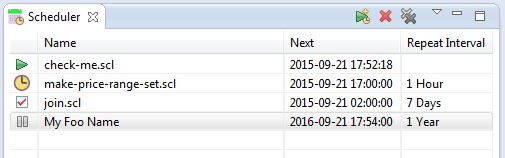
Automate the execution of local or remote jobs in Workbench with Voracity's integrated task scheduler:
Because the jobs developed in the GUI are serialized as scripts in batch and XML flow files, you can run them on the command-line, too:
That means you can run Voracity jobs as a system call from any application, or from third-party workload automation tools like CA Autosys, cron, ACSI ActiveBatch, Oracle Job Scheduler, Stonebranch Universal Controller, etc.
Yet another way you can run Voracity jobs like CoSort -- to prepare data for analytic display in IRI Workbench -- is via BIRT or KNIME in Eclipse. BIRT users can leverage an IRI Data Source at reporting time through the ODA driver per this example. KNIME users can leverage the Voracity data source node (provider) in KNIME workflows per this example.
